
Страница - 26
Заключение
Поиски новых способов представления значения, смысла и содержания текстовых единиц в памяти лингвистических автоматов идут в самых разных направлениях [3, 191, 203, 228, 234].
Одно из них связано с последними достижениями науки о лингвистике текста, а именно с тем, что основной единицей письменной коммуникации является не предложение, а текст.
В этой связи, процессуальный, динамический подход к изучению языка, подход через изучение процессов, лежащих в основе порождения и понимания высказываний, позволит выявить ту роль, которую играют при формировании содержания текста лингвистические и энциклопедические, детерминированные правила и случайные факторы, языковые и логические структуры мышления [117, с.256; 154, с.51).
Ссылаясь на точки зрения лингвистов, психолингвистов и других специалистов на структуру текста, а именно на его составляющие, связь текста с языком, мыслью к реальной действительностью, можно выделить характерные черты текста, такие как наличие в нем единого содержания, определенных его единиц. Эти единицы текста связаны между собой как семантически, грамматически, так и ло- гически. Причем, замечается неоднозначность таких связей между основными единицами данного текста.
Содержание текста следует понимать как отражение в сознании человека отношения линейной цепочки имен текста к трансформированной автором, в соответствии с замыслом, целями и условиями коммуникации, психической ситуации. Причем, релевантными для организации содержания текста являются две группы абзацев, выделенные по функционально-смысловому критерию и месту в структуре текста (начальные, медиальные и конечные).
Проанализировав высказывания ученых разных направлений и специальностей с роли вероятности в общей теории познания, процессах функционирования языка и организации различных текстов, мы можем сделать следующие выводы:
- все связи в реальном мире носят объективный характер, что проявляется в массе однородных явлений;
- язык, являясь саморегулирующей системой, при порождении речи функционирует, используя как детерминированные правила, так и случайные факторы;
- текст как результат речевой деятельности также содержит детерминированные и вероятностные составляющие;
- абзацы как “кванты” содержания и “застывшие” синтаксические шаблоны организуются в единое целое по вероятностноалгоритмическому принципу.
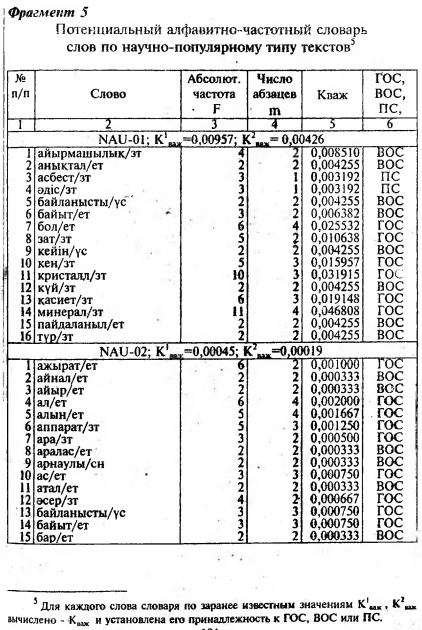
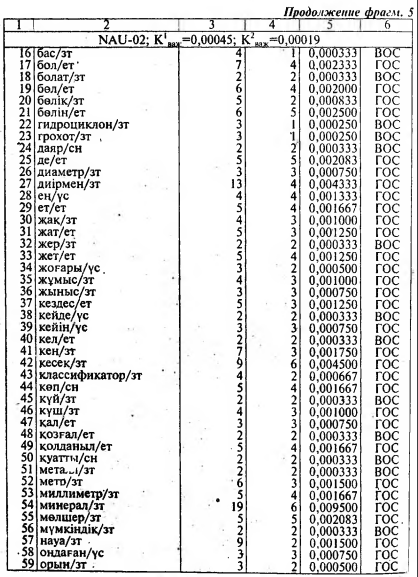
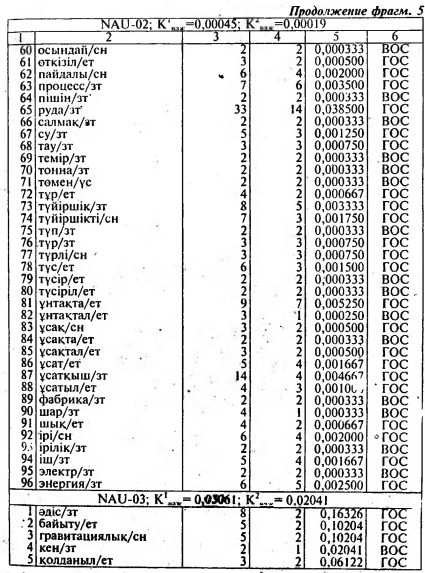
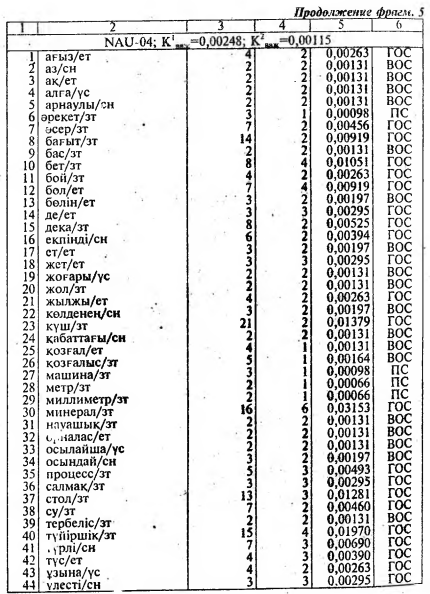
Анализ конкретного материала, содержащего 102 минитекста в трех жанровых разновидностях позволил нам предложить формальный критерий - коэффициент важности , позволяющий отделить опорные слова казахского текста от остальных его слов. При этом удалось дифференцировать К важ на два критерия - К1 важ и К2 важ позволяющие выделить главные и второстепенною опорные слова в трех функционально-смысловых типах казахского текста. Следует отметить, что значения коэффициентов этого критерия отличаются от соответствующих коэффициентов критерия важности, использованных для определения опорных слов в русскоязычных текстах (128, с.18-19].
Выделенные по указанному критерию опорные слова казахского текста (ГОС, ВОС), сыграли определенную роль в разработке построения “Таблицы основного статического содержания” в рассматриваемых нами 102 минитекстах.
Таким образом, подход к абзацу как к минимальной семантикосинтаксической единице текста позволил нам выделить в трех исследованных текстах определенные типы абзацев по их функционально-смысловому содержанию, структурному положению в тексте (начальный, медиальный, конечный), а также по предметнологическому содержанию.. Выделенные типы во всех указанных разновидностях текстов исследованы статистически.
Приступая к построению алгоритма порождения текста, разумно проявить некоторую осторожность и принять ряд ограничений |118, с. 14]. Одним из таких ограничений исследования является выбор текстов конкретных авторов, представляющих три различных функционально-смысловых типа речи: рассуждение, повествование и описание. Следующее допущение, принятое нами, заключается в том, что тексты одного и того же автора могут быть представлены в виде ограниченного кванта содержания, в качестве которого мы приняли предметно-логическое содержание абзаца как основной единицы письменного текста. Анализ, с этой точки зрения, трех нами рассмотренных функционально.-смысловых типов позволил выявить в них ограниченное число абзацев, из комбинации которых построены исследуемые тексты. Таким образом, установлено количество общих типов абзацев для всех исследованных текстов. В эту монографию не вошли данные, полученные на основе изучения вероятностей следования абзацев, которые также необходимы для составления алгоритмов порождения казахских текстов. На наш взгляд, такой вопрос требует особого рассмотрения для тюркоязычных текстов.
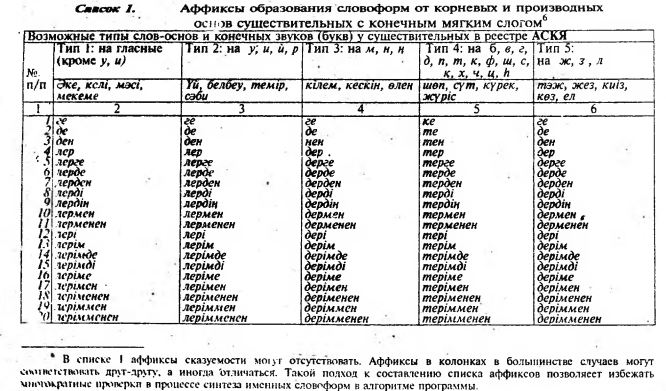
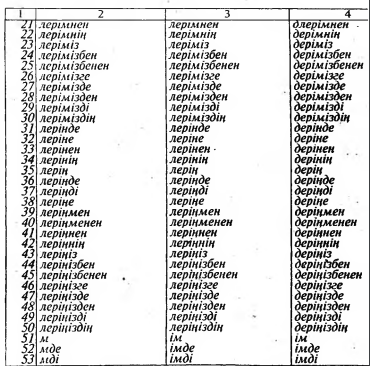
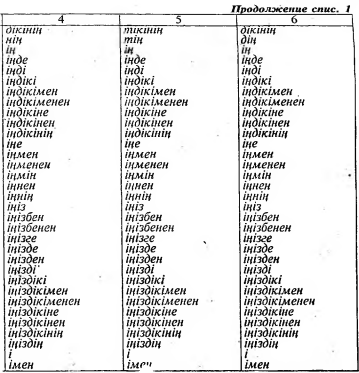
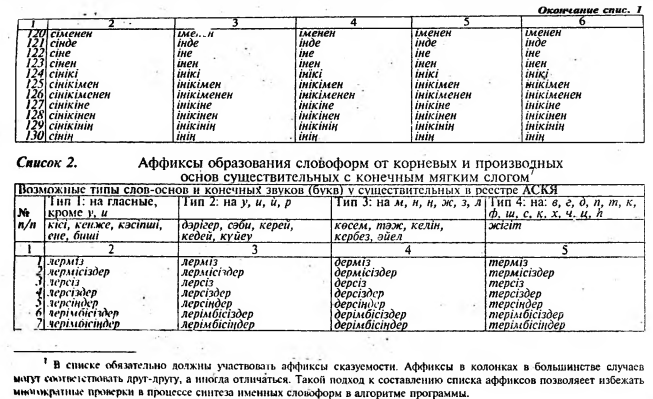
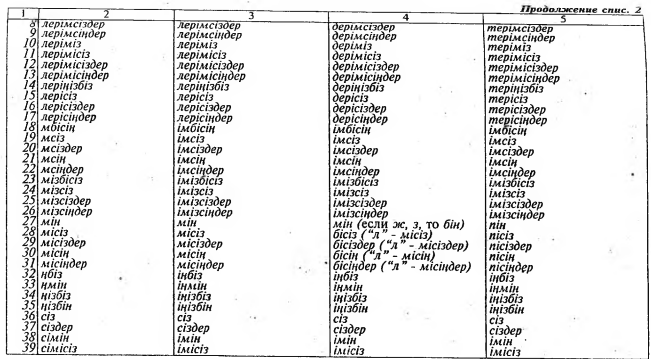
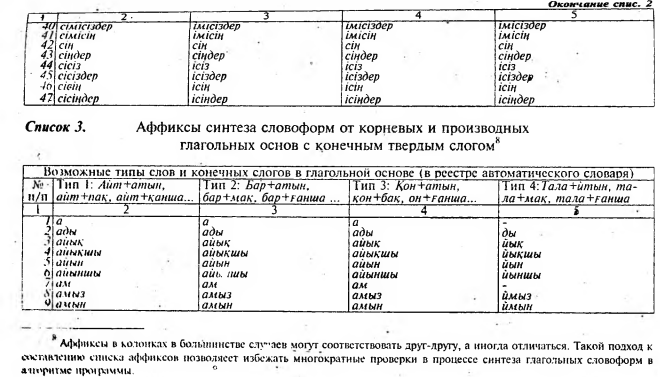
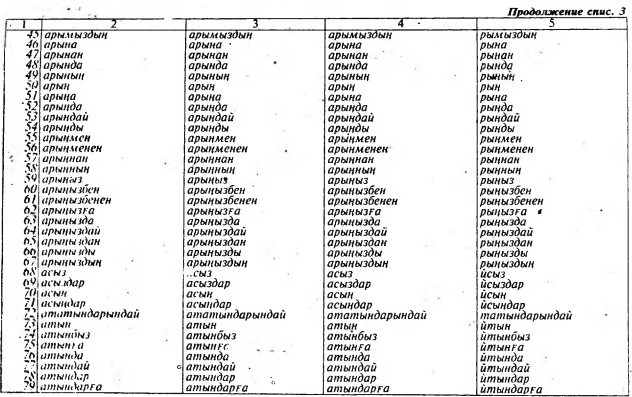
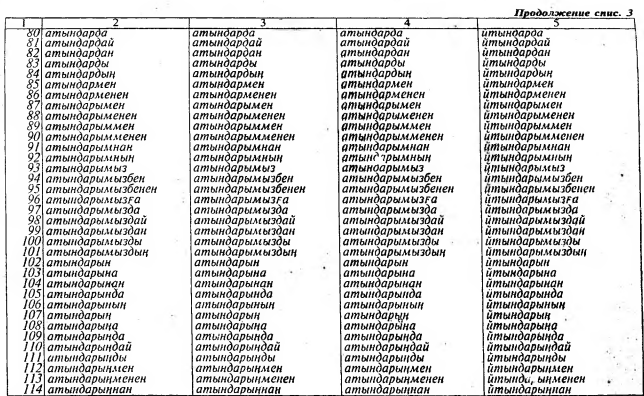
Важным моментом нашего исследования явилась семантическая [классификация знаменательных классов слов казахского языка (см. табл. 3-10) и их кодификация, которая позволяет передавать некото- рую жизненную ситуацию, описываемую в тексте.
Говоря об алгоритмах и программах порождения текста, нельзя не упомянуть известного ученого К. Шеннона, так как с его исследованиями связан алгоритм порождения цепочек слов, в котором учитываются вероятности употребления отдельных букв, пар букв, троек, четверок букв и т.д.- [312]. Он показал, что чем на большую длину буквенных последовательностей учитывались связи, тем более [осмысленными получались слова.
Достаточно большое число алгоритмов и программ было разработано исследователями для подтверждения тех или иных синтаксических и семантических моделей предложений. Но в них нет единого замысла, нет смысловых опорных точек, отсутствуют строгие смысловые критерии отбора синтаксических и лексических единиц [128].
Следует отметить, что формального построения правильных и осмысленных предложений можно достичь только при комбинировании детерминированных и случайных процессов порождения текста [129, с.182].
Интересны эксперименты, проведенные по составлению алгоритмов сочинения различных сказок на ЭВМ [72]. В основе всех попыток сочинения сказок формализованным путем лежат исследования структуры сказок, проведенные В. Проппом [238]. В частности, в одном из алгоритмов порождения сказки в качестве исходной информации приняты следующие данные: перечень типов действующих лиц, перечень типовых характеристик персонажей, список возможных поступков каждого действующего лица, список возможных типов встреч и т. д. В итоге получается некоторая общая формула сказки [72, с.223]. Для более ясного представления об этом запишем небольшой отрывок из казахской сказки “Әділ жаза” (“Справедливое наказание’’) [165, с.73-79], основываясь на принципах этой формулы: "Ерте-ерте ертеде, ешкі кұйрығы келтеде, бір “А ” болыпты. “А ”-нын }’«< баласы бар екен. Ен үлкенінің аты - “Б”, ортаншысының аты - “В”, ал кенже баласынын аты - “С”екен. “С"ате <а>, <В>, әрі <ү>, <р> бала болып өседі. “А” уйыктап жатып <d> кареді, <d>-da бір ғажайып <е> көреді. <е> күлсе, аузынан буда-буда <g> түседі, жы.іа- са, козінен <z> пгүседі. Міне, “А” осы <е>-ге ынтық болады. Дереу ор- нынан түрькымен “Б” мен “B’’-ны шақырып алып көрген <d> -ны ай- тып береді... ”.
Участвующие в сказке условно принятые обозначения на самом деле означают: “А” - патша (царь), “Б” - Асан (имя старшего сына), “В” - Үсен (имя среднего сына), “С” - Хасан (имя младшего сына) <а> - сүлу (красивый), </?> - ақылды (умный), <у> - батыр (смелый), <р> - ак көңілді (веселый), <d> - түс (сон царя), <е> - кр (волшебная птица), <g> - гул (цветы), <z> - мониіак-мдншақ маржаі (бусы из драгоценных камней) и т. д.
Теперь А, Б, В, С и <а, р, у, р, d, е, g, z> и т. д., заменив другими действующими лицами вместе с их характеристиками, поступками и т. д., можно получить сколько угодно вариантов казахских сказок, созданных по этой формуле.
Стоит заметить, что общение с компьютером (ЭВМ) на естественном языке еще далеко от совершенства. В искусственных языках, понятных для машин, множество элементов формируется отношением эквивалентности, в естественном же языке, например казахском, такое объединение единиц проводится на основе толерантности или сходства.
Известно также, что основная особенность языковых множеств - наличие в нем нечетких, размытых границ, причиной которых является несовпадение структур естественного и искусственных языков. Такое несовпадение Р. Г. Пиотровский [228] считал следствием известных антиномий языка и речи, дискретности и непрерывности, синхронии и диахронии, языка и диалекта, предложенных еще Ф. де Соссюром [260].
Как мы полагаем, в использовании современной компьютерной техники в Республике Казахстан значительная роль должна отводиться созданию лингвистических процессоров, основанных на применении знаний, заложенных на естественном казахском языке. Благодаря этому, современные компьютеры не просто будут осуществлять накопление и поиск информации на национальном языке, но и будут понимать смысл запроса, а также выдавать результаты в виде текста и речи на казахском языке. Однако, создание таких лингвистических процессоров будет опираться на ограниченные языки определенных предметных областей (подъязыки).
Известно, что в каждом языке выделяются функциональные стили или “подъязыки”, которые обладают, по сравнению с языком в целом, ограниченным количеством лингвистических единиц и определенной спецификой их употребления. Выбирая наиболее частые и информационно насыщенные единицы языка, а также типовые контексты их употребления, мы можем построить такую модель языка (базовый язык), которая будет являться некоторым приближением к реальной системе подъязыка, порождающей тексты узкой тематики [231, с.21-23].
Особую ценность в республике в настоящее время представляет так называемая “деловая проза”, написанная на казахском языке, а также армейские документы (“военная деловая проза”) и национальный военный лексикон, который только начинает зарождаться в армейской жизни.
Таким образом, научные исследования в этом направлении, т.е. анализ и синтез текстов указанных документов, являются неотложной задачей ученых-казаховедов и специалистов по инженерной лингвистике.
Дальнейшее изучение проблемы порождения казахского текста требует более глубокого рассмотрения всех вопросов, касающихся семантико-синтаксических формул предложения, абзаца и текста в целом. И, конечно же, необходим практический анализ больших объемов текстов самых различных типов с помощью предложенного искусственного языка СЕМСИНТ для. выявления и написания различных семантико-синтаксических формул этих текстов.
ПРИЛОЖЕНИЯ










Фрагмент 6
В пятой главе книги на основе осмысления содержании и анализа статистических данных следующих минитскстов были составлены: 1) XUD-03: табл. 26 — фрагмент потенциального алфавитно-частотного распределительного словаря, табл. 28 — таблица основного статического содержания (ТОСС); 2) PUB-06 табл. 29 — таблица основного статического содержания; 3) NAU-15 табл. 30— таблица основного статического содержания.
Ниже приводим эти минитексты, относящиеся к трем функционально-смысловым типам как повествование, описание и рассуждение:
XUD-03:
Сейсенбаев ояздык аткару комитетінін нүскауіиысы еді. Ояздық атқару комитеттен Борлыкөл елінің болыстык атқару комитетінің бір шатақ жүмыстарына барған. Қайтып келе жатып, Шиелі поселкесінін ар жағында 10—15 іиақырымдай жердегі, бүрын би болған, белгілі, ақсак Ақан дегендікіне қоныпты. Іңірде ас пісіп, Сейсенбаев, ақсак Ақан және үш-төрт ауыл кісілері табақты жаба алдарына алып, еттiң буын бұркыратып турай бергенде, үйге сол ауданда жүрген белгілі банды Кудря кіріп келіпті. Кудря жұрттың айтуынша жэне істеп жүргендеріне карағанда, өзі балуан, жасаулы мылтыктан тайсалу дегенді білмейтін, талайларды өлтірген. Міне, сол Кудря қасында ешкім жок, алтыатарын қолына үстап, үйге кіріп келіп тура калыпты:
— Кәне, мынау отырған исполкомның нүскаушысы болса, тысқа шыксын! — депті.
Сейсенбаев жылап коя беріп, ақсақ Аканның артына тығылып, күшактап жалыныпты. Сол жерде аксак Акан араға түсіп, Кудрины тоқтатып, Сейсенбаевты аман алып калыпты. Сейсенбаевка білдірмей, біреу политбюроҒа мүны қүпиялап баяндапты...
Міне, енді, Кудряның ізін, кімдермен байланыс қылатынын астыріпын жансыз жүріп біліп, үспгауға әрекет қылуға политбюро Хймитті жүмсап отыр. Кудряның шарлап жүрген ізінің үиіығын казак арасынан оцайырак табуға мүмкін ғой деп ойласып, Хамиттін баруын макүлдады.
Хамит кешікпей керек-жарак саймандарының бэрін түгелддеп алып, бес орыс жолдаспен жүріп кетті.
Акмо. іға баратын үлкен жолмен жүріп келіп, Шиелі поселкесіне таянғанда Хамит жолдастарымен жүріс-түрыстын, байланысып, хабарласып отырудың жобасын эбден акылдасып, жасасып алып, жолдастарын қоя беріп, өзі бұрылып казак аулына кетті.
Хамит — үзынша бойлы, жауырынды, тіп-тік, сүр жігіт. Қырша мүрынды, шүціректеу кара кер тобылғы квзді, кыркып жүретін сакалы, мүрты бар. Жасы 25-26 шамасында. Сом, сүлу денесі ылғи сіңірмен шиырылған күіиті 'көк ет еді. Бар денесі серіппелі көк темірден күйып жасағандай. Түйіліп жазылған киғаштау касы мен шұнғылдау квзі Хамитте зор кайрат, үлкен кайсарлык бар екеніц көрсетеді. Бет-аузы бүркіттің бетіндей. Қыран бүркіттің түрпілі

