
Страница - 10
2.3.3. Структура автоматического словаря казахского языка
С учетом того, что “слово” любого языка по своей природе является сложным лексико-грамматическим единством, необходимо проводить разделение слов на определенные структурные группы или типы, согласно выбранному для каждого случая принципу классификации.
Наш принцип создания автоматического словаря казахского языка' (АСКЯ) преследует частный случай и не претендует быть универсальным словарем, охватывающим все случаи исследовательской практики. В основе нашего АСКЯ лежит алфавитный словарь слов- основ казахского языка, где к каждому слову представлена лингвистическая информация - словарная статья, которая представляет собой отдельные зоны (области памяти), в которых записана условно принятая нами кодовая информация о некоторых .морфологических, фонетических, семантических, синтаксических и других признаках (параметрах) рассматриваемого слова. Слово-основу, в данном случае, следует понимать как звуковой комплекс с определенным значением, представляющий собой корневые и производные (аффиксальные) слова, относящиеся к определенному классу слов казахского языка. Слово-основа и есть основная лингвистическая единица АСКЯ, к которой приписана соответствующая словарная статья, состоящая из лингвистической (и энциклопедической) информации, записываемой в виде формально принятых нами кодов в указанном номере зон. Количество зон для каждой единицы словаря будет зависеть от максимального количества “досье” к данному слова. Причем каждая зона с одним и тем же номером должна иметь информацию одного и того же типа (содержания). Например, зона сообщает информацию о принадлежности рассматриваемого слова определенному классу слов: существительное, глагол, прилагательное и т.д. При этом некоторые зоны для отдельных слов “временно” могут иметь “нулевую” (пустую) информацию до тех пор, пока его со держание окончательно не выяснится. Это даст возможность постоянно редактировать и расширять объем “досье” к слову.
Схематически АСКЯ имеет следующий вид:

В случае, когда содержание информации для данной зоны “компактное”, в смысле занимаемого объема памяти, то его можно поместить в соответствующем выделенном номере зоны. Если жесткая информация о слове требует дополнительного объема памяти (чем выделено) или же она еще не существует в готовом виде, то та кая зона должна иметь соответствующую команду, отсылающую и выполнение задания по поиску или созданию такой информации Например, при синтезировании всевозможных словоформ для данного слова-основы или же при снабжении данного слова контекстных примерами из разных иллюстрационно-текстовых источников. Этот факт говорит о том, что “досье” к слову в автоматическом словаре может быть не всегда доступным потребителю непосредственно т.е. оно не всегда известно в готовом виде. В таких случаях должен быть указан путь достижения цели (алгоритм). Иначе говоря, в этом случае необходимо провести соответствующее исследование по заранее указанному алгоритму и формировать требуемую информации для данной зоны.
Таким образом, АСКЯ должен как бы обладать “пониманием” известных языковых законов, т. е. по возможности в АСКЯ должны быть смоделированы синхронные и диахронные языковые процессы, которые представлены в динамике, позволяющие функционировать отношения единиц, уровней, подсистем и т.д. Следовательно, автоматический словарь казахского языка (АСКЯ) должен существовать в компьютере не как готовая книга-словарь, а как научная лаборатория, банк научных знаний об объекте (в данном случае, о казахском слове). В перспективе АСКЯ должен стать не только хранилищем знаний о языке, но и представлять собой “разумный”, специализированный банк знаний, способный предложить решение или нацелить исследователя на определенное решение.
По нашей версии, порядок расположения информации, т.е. информация в соответствующих номерах зон, может быть произвольным, но стандартным для всех единиц словаря.
Содержание словарной статьи в АСКЯ в начальных номерах зон, по предлагаемой нами версии, должно выглядить так, как это изложено ниже:
Зона 1. Слово из автоматического словаря принадлежит к одному из ниже перечисленных классов слов:
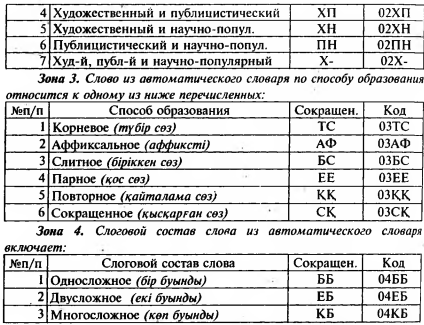
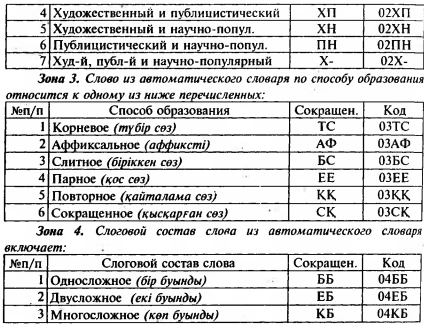
Зона 5. Слово из автоматического словаря относится к соответствующему семантическому классу.
В третьей главе нами проведено исследование по семантической классификации знаменательных классов слов казахского языка (существительное, глагол, прилагательное, наречие и местоимение). В табл. 3-10 указанной главы показаны содержания (примеры) семантических классов и подклассов указанных частей речи, а также условные компьютерные коды соответствующих подклассов. Данные этих таблиц позволят заполнить “зону 5” словарной статьи для соответствующей лексемы АСКЯ.
Таким образом, все изложенное по первым пяти зонам на примере парного слова “эке-шеше ” в АСКЯ будет иметь следующий вид:
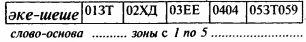
Ввиду того, что порядок расположения информации в словарной статье может быть произвольным, то далее, по усмотрению создателя АСКЯ, можно продолжить все предполагаемые лингвистические и энциклопедические информации в их кодовых значениях и помещать в предназначенных для них зонах словарной статьи. .
Раскодирование информации в понятном для лингвиста (или для любого интересующего словарем) виде и поиск необходимой ин- фомации в словарной базе и др., как мы уже отмечали, - дело специалистов по созданию компьютерного АСКЯ.