
Страница - 22
5.3. Способ выделения опорных слов казахского текста
Как мы отмечали, основными критериями при выделении опорных слов текста являются абсолютная частота употребления слова <с учетом всех возможных замен) и количество абзацев, в которых встретилось слово, кроме этого, такой критерий не должен зависеть от общего числа слов в тексте.
Наиболее удобной для нас представляется несколько измененная формула коэффициента статистической устойчивости термина (187, с.87]:

где Ғ - абсолютная частота слова в тексте (в нее входит суммарная частота всех типов синонимов этого слова и местоименных замен); т - число абзацев, в которых встретилось слово; N - общие число слов в тексте; п - общее число абзацев в тексте.
Назовем этот критерий Кваж коэффициентом важности слова и определим для слов всех анализируемых текстов его критические значения К1важ и К2важ, позволяющие формальным способом отделить в массе слов конкретного текста соответственно главные и второстепенные опорные слова.
Эксперименты по выделению опорных и неопорных слов наших трех видов текстов, проведенные на текстах самой различной длины (от одного абзаца до 100), дают нам возможность предложить на основе формулы (1) эксприментальным путем составленные нами две формулы-неравенства (2) и (3):
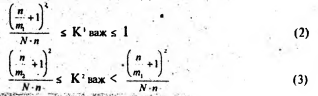
С помощью этих неравенств можно определить левые и правые границы отнесения потенциальных слов к ГОС и ВОС для текстов на казахском языке.
Здесь неравенство (2) служит для определения границ ГОС, а (3) - для ВОС. Значения коэффициентов т1 и т2, участвующих в формулах, зависят от общего числа абзацев в тексте и поэтому они были нами подобраны экспериментальным путем. Значения т1 и т2 будут зависеть от интервалов, в которые попадет значение п - общее число абзацев в тексте. Например, для К1 важ (т.е. для ГОС), если общее число абзацев п более 100 или равно 100, то m, = 42, а если п более 60, но менее 100, то т1 = 30 и т.д. Полный перечень значений для т1 и т2 (для ГОС и ВОС) и соответствующие им формулы нера- венств для K1 важ и К2важ. приведены в табл. 21 ив табл. 22.
Таким образом, можно предложить следующие критерии:
- к главным опорным словам (ГОС) текста будем относить те слова, которые удовлетворяют требованиям, определенным в т.5л. 21;
- к второстепеным опорным словам (ВОС) того же текста относятся те его слова, которые удовлетворяют требованиям, определенным в табл. 22;
- все оставшиеся слова текста считаем неопорными словами и будем называть их прочими словами (ПС).
В то же время слова, входящие в каждую из первых двух полученных групп, неоднородны по содержанию. В соответствии с предметными свойствами референтов они образуют группы опорных слов - субъектов, объектов, слов-мест и слов-времен [73, с.23; 183, с.15-51; 307, с.105]. Именно они совместно с предикатами выражают взаимосвязи основных, объективно существующих, категорий: материи, движения, времени и пространства [183, с.15-51].


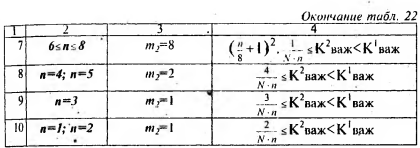
5.4. Выделение опорных слов в трех анализируемых типах текстов
Как видно из предыдущего пункта, для того чтобы выделить опорные слова конкретного текста, необходимо знать общую частоту употребления слова в тексте и распределение этого слова по абзацам текста. Чтобы получить эти данные для каждого текста рассматриваемых нами трех функциональных типов текстов, необходимо составить так называемый распределительный алфавитно-частотный словарь употреблений слов по абзацам. В этом словаре приводятся алфавитные списки всех слов, встретившихся в каждом абзаце, с указанием частоты употребления каждого слова в этом абзаце. Далее проводится объединение словарей абзацев в единый алфавитный словарь текста. При таком объединении суммируются частоты одинаковых слов и подсчитывается число абзацев, в которых встретилось каждое слово. При объединении слов учитываются отмеченные четыре способа замен в тексте: словарный синонимический, контекстуальный синонимический, местоименный и ассоциативный. Все это делается с опорой на содержание каждого текста.
На следующем шаге анализа из полученного алфавитно- часттного словаря отдельно выделяются имена существительные (и именные словосочетаниях) и другие слова, относящиеся к знаменательным классам слов казахского языка, имеющие частоту Ғ, равную двум и более, с указанием всех возможных замен в тексте и числа абзацев, в которых встретились эти слова. Такие слова располагаются в порядке убывания их абсолютных частот Ғ и образуют потенциальный словарь опорных слов. Этот словарь служит основой для разделения опорных слов на главные и второстепенные и выделения внутри них различных подгрупп опорных слов.
В нашем эксперименте были рассмотрены три вида текстов по функционально-смыловому типу: 1) научно-популярный стиль - изучены 47 различных по объему (по количеству слов) минитекстов по одной тематике; 2) публицистический стиль (газетные статьи) - 35 газетных статей по одной рубрике (или 35 различных по объему мини-текстов); 3) художественный стиль - 20 минитекстов различного объема (рассказы видных казахских писателей).
По изложенной последвательности на основе специально составленных нами компьютерных программ были получены алфавитно-частотный распределительный по абзацам словарь по отдельным текстам каждого типа и объединенный словарь по трем типам казахских текстов. (Во второй главе мы уже приводили перечень полученных на компьютере словарей. Фрагменты этих словарей будут показаны в Приложении.)
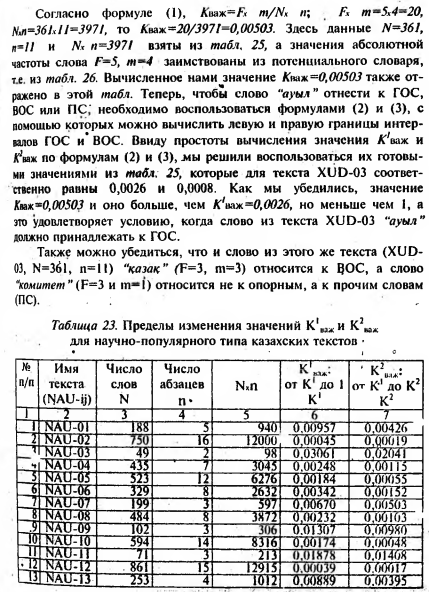
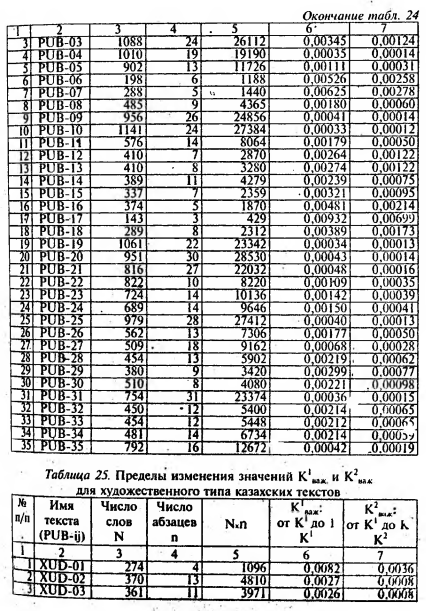
Далее из этих распределительных словарей были получены так называемые потенциальные словари, которые являются базовыми словарями для определения ГОС, ВОС и прочих слов рассматриваемых текстов. Для отдельного типа текстов и входящих в него мини-текстов по известному общему числу слов в тексте N, общему числу абзацев в каждом мини-тексте п заранее были вычислены пределы изменения К1важ и К2важ, которые приведены в табл. 23 для научно-популярных текстов, в табл. 24 - публицистического и в табл. 25 - художественного текста.
Для того чтобы читатель имел некоторое представление о таких словарях, приведем фрагмент (отрывок) потенциального словаря в виде табл. 26, рассматривая XUD-03 (художественный) и слова, от носящихся к классу существительных.
В потенциальных распределительных алфавитно-частотных словарях для каждого слова нами вычислены значения Кваж. Сравнением Аваж со значениями К1важ и К2взж из табл. 23, 24, 25 (согласно типу текста), установлена их принадлежность или к ГОС, или к ВОС, или к ПС. Эти сведения записаны в последней графе табл. 26 (фрагмент потенциального словаря по XUD-03).
Поясним (для филологов), как определяется принадлежность слова к опорным словам, согласно предлагаемой нами методике.
Для примера рассмотрим слово “ауыл" (село), из потенциального словаря, составленного по тексту XUD-03, N=36], n=11, (табл. 26 и 26).

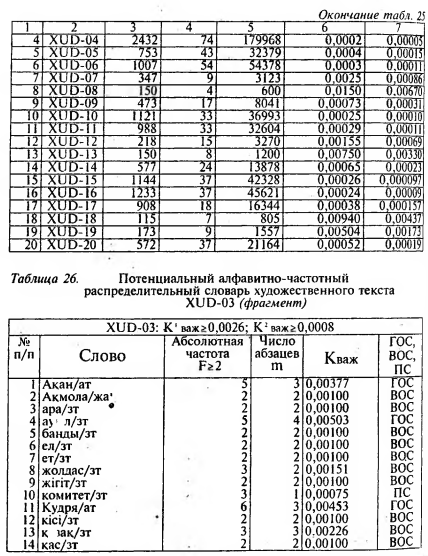
Индексы в конце слов (после наклонной черты - /), означают принадлежность слова к классу слов. В табл. 26: "ат" сокращение от адам аты (имена людей), жа - жер аты (название местности) и "зт" - зат есім (существительное).